Serverless Architecture in WeSQL
This article explores how WeSQL achieves serverless functionality. We delve into the designs that empower WeSQL to offer a scalable, cost-effective, and developer-friendly serverless MySQL solution.
Foundation of Serverless: Compute-Storage Separation Architecture
WeSQL adopts the compute-storage separation architecture:
- Compute Nodes (WeSQL Data Node/Logger Nodes): Responsible for processing queries and transactions.
- Storage Layer (S3): Stores all persistent data, including database files, binlogs, and metadata.
This separation allows WeSQL to independently scale compute and storage resources. Even if the computation nodes scale down to zero, the data remains fully persisted in S3, ensuring no data loss.
Gateway/Frontend for Serverless Traffic: WeScale
WeScale is the core component of WeSQL's serverless architecture, functioning as both a database proxy and a resource manager:
- As a MySQL proxy, it manages client connections and routes queries to the backend WeSQL data nodes.
- As a resource manager, it implements intelligent resource management features, such as automatic suspension and scaling, based on traffic and load.
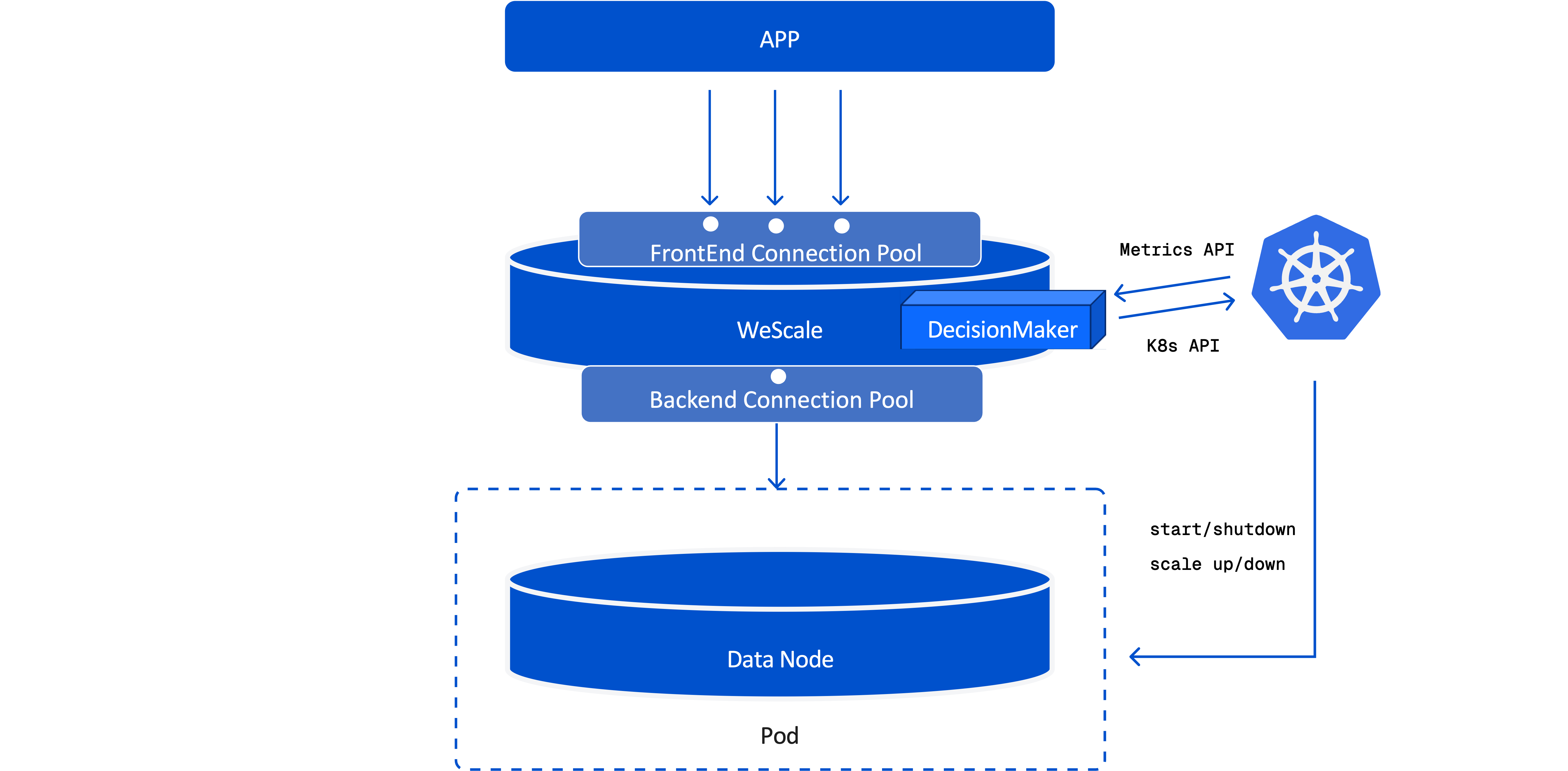
WeScale plays a pivotal role in enabling the serverless functionality of WeSQL:
Connection Pool
One key design point in a serverless architecture, especially when scaling compute nodes down to zero, is maintaining uninterrupted client connections. WeScale addresses this by holding TCP connections with user applications and keeping client connections alive, even when no compute nodes are running. Upon receiving a new query, WeScale triggers a scale-out process immediately, bringing up compute nodes and, once the nodes are ready, forwards the SQL query to ensure that the client's request is successfully executed.
Query Routing and Service Discovery
WeScale features dynamic backend discovery, allowing it to automatically detect the addition or removal of compute nodes. When compute nodes restart or scale out from zero replicas, WeScale automatically connects to the available WeSQL data nodes. In future versions of WeSQL, which will support multiple data nodes (e.g., read-only nodes), WeScale will handle query load balancing, ensuring that queries are seamlessly distributed across available compute nodes.
Triggering Auto-Suspend and Auto-Scale Decisions
If you deploy WeScale on Kubernetes, WeScale is responsible for the automatic scaling and suspension of compute resources, enabling WeSQL to adapt seamlessly to fluctuating workloads while optimizing resource utilization and cost.
Although WeSQL and WeScale can run in environments like containers and virtual machines, Auto-Suspend and Auto-Scale only function when WeSQL and WeScale are deployed in a Kubernetes environment. This is because WeScale relies on the following Kubernetes features to enable these capabilities:
- Metrics Server: Resource metrics are collected via Kubernetes' Metrics Server, providing real-time data for scaling decisions.
- K8s Pod API: WeSQL manages the number of compute node pods and their resource allocations through Kubernetes' Pod API.
- InPlace Pod Vertical Scaling: Utilizing Kubernetes' InPlace Pod Vertical Scaling (enabled via the
InPlacePodVerticalScalingfeature gate), WeScale can adjust resource allocations without restarting Pods, ensuring minimal disruption during scaling events. As of Kubernetes 1.31,InPlacePodVerticalScalingis still in alpha version. You can experiment with this feature in GCP GKE's alpha clusters.
AutoSuspend
To optimize resource utilization and reduce costs, WeScale implements an automatic suspension mechanism:
- Idle Detection: WeScale monitors the activity of compute nodes. If a node remains idle (i.e., not processing queries) for a specified timeout duration, WeScale suspends the node by scaling it down to zero resources.
- Scale to Zero: WeScale can scale compute resources down to zero, effectively reducing resource usage to zero. This is particularly beneficial for development and testing environments or applications with infrequent access.
- On-Demand Resumption: When a new query arrives for a suspended node, WeScale automatically triggers the scale-out process. The compute node is provisioned, restores its previous state from S3, and begins processing the query.
One challenge of AutoSuspend is optimizing and reducing the latency of processing the first query after a compute node is awakened from a suspended state (Cold Start). In WeSQL, we can have the WeSQL-Server complete a snapshot before suspension, which can improve the startup speed of the WeSQL-Server.
AutoScale
WeScale monitors the workload in real-time and adjusts the resources allocated to active compute nodes accordingly:
- Resource Monitoring: WeScale collects metrics on CPU and memory utilization of the compute nodes through Kubernetes' Metrics Server.
- Decision Module: Based on predefined thresholds (e.g., CPU utilization at 75%), WeScale decides when to scale resources up or down.
- Vertical Scaling: WeScale adjusts the CPU and memory resources of compute nodes based on workload demands, scaling them up when demand increases and scaling them down during periods of low activity.
- InPlace Resource Updates: By leveraging Kubernetes' InPlace Pod Vertical Scaling feature, WeScale can adjust the resources allocated to pods on-the-fly, enabling vertical scaling without restarting the pods.
Use Cases
WeSQL's Serverless model is ideal for the following scenarios:
- Variable Workloads: Applications with fluctuating traffic patterns, such as web applications or seasonal services, benefit from automatic scaling and suspension, including scaling to zero during idle periods.
- Development and Testing Environments: Databases can be provisioned and suspended on demand, minimizing costs during downtime while ensuring instant availability when needed, all without manual intervention.