LSM Storage Engine
In WeSQL, we developed an LSM-based storage engine named SmartEngine as a drop-in replacement for InnoDB. The LSM tree (Log-Structured Merge-Tree) is a data structure well-suited for write-intensive workloads. It appends data during writes instead of updating existing data, making it ideal for S3, which does not support random writes.
In contrast, InnoDB uses a B+ tree data structure, which generates a significant amount of random writes. This random write pattern is incompatible with S3, as object storage does not support such operations. While it's possible to convert InnoDB’s page modifications into an append-only format, this approach would lead to write amplification.
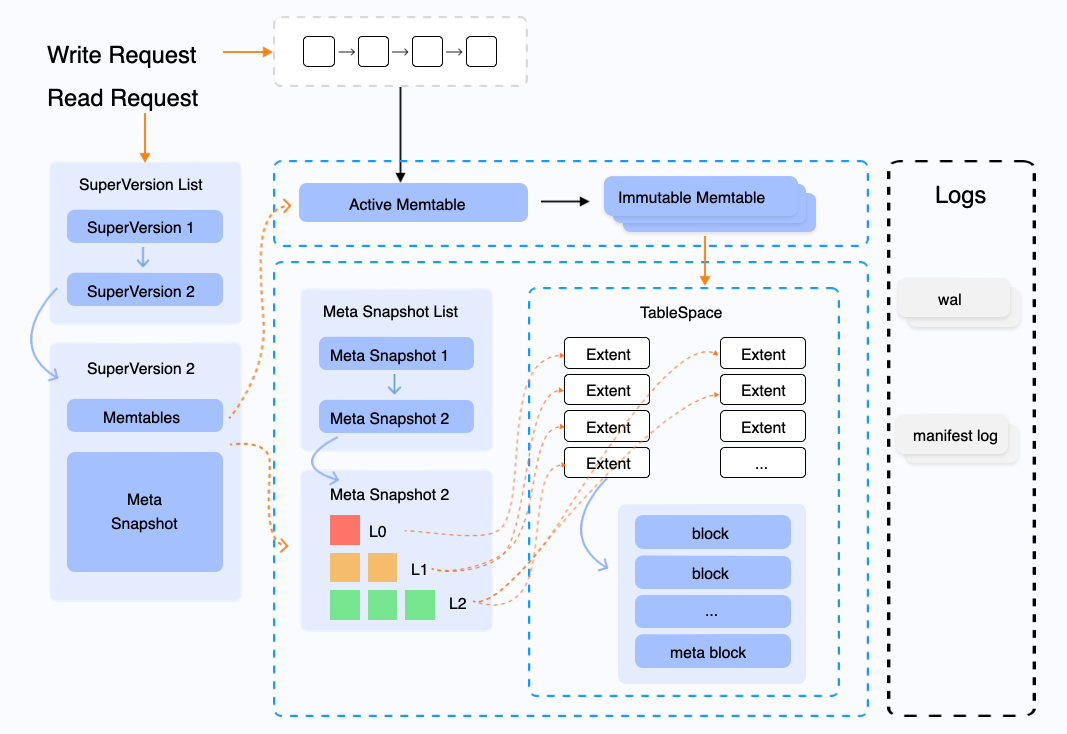
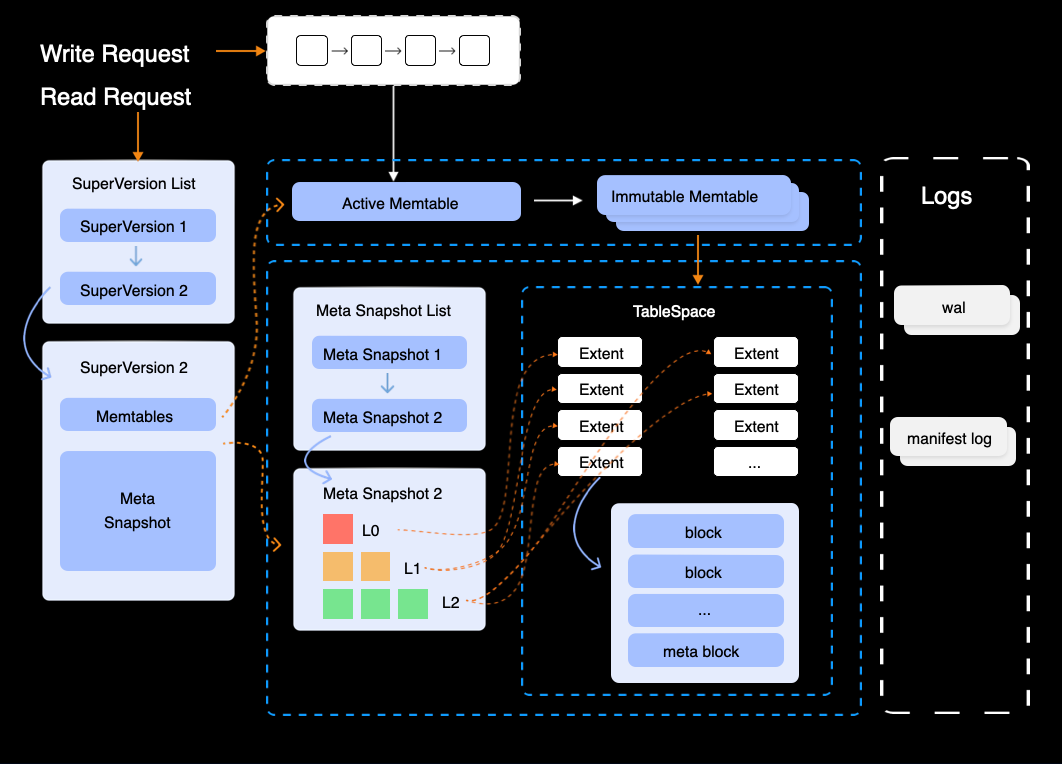
Structure
In SmartEngine, the LSM data structure consists of a MemTable, multiple Immutable MemTables, and a three-level tree structure: L0, L1, and L2 (there are only 3 levels, no more). Each level (L0, L1, L2) contains multiple extents, where each extent is 2MB in size and corresponds to a single object in S3. In SmartEngine, each index has its own independent LSM data structure. This means that if you have a table with both a primary key index and a secondary index, the table will have two separate LSM structures—one for each index.
Extents are contained within a tablespace, and the data of a table and its indexes are stored within that tablespace, which is generated when the table is created. This design ensures efficient organization and storage of both table data and index data across the different levels of the LSM structure.
Concepts
WAL
The Write-Ahead Log (WAL) is a key component of SmartEngine's durability and crash recovery mechanisms. When data is written to SmartEngine, it is first recorded in the WAL before being added to the in-memory MemTable. This ensures that even if a crash occurs before the data is fully persisted to S3, the WAL can be replayed during recovery to restore the in-memory state and ensure no data is lost. In SmartEngine, the WAL (Write-Ahead Log) is a global object, meaning that there is only a single WAL stream on a given node. All write operations for all tables and indexes are recorded in this single WAL.
MemTable
The MemTable is an in-memory structure where newly written data is temporarily stored before it is flushed to disk. It acts as a buffer for written data, allowing for fast writes and retrieval. The MemTable is also sorted, which enables efficient querying and retrieval of data while it resides in memory. When the MemTable reaches a certain size, it is flushed to disk as a new Level 0 (L0) in the LSM tree. The data in the MemTable is also backed by the WAL to ensure durability.
L0,L1,L2
In SmartEngine, data is organized into a Log-Structured Merge Tree (LSM Tree), which consists of multiple levels:
- L0 (Level 0): This is the initial level where flushed data from the MemTable is stored. L0 layers are unsorted and may overlap in key ranges.
- L1 (Level 1): As L0 layers accumulate, they are compacted and merged into L1, which is sorted and non-overlapping in key ranges.
- L2 (Level 2): L1 layer is further compacted and merged into L2, which is larger and more optimized for reads. Each level is progressively larger and more compacted than the previous, ensuring efficient storage and fast access to frequently read data. The LSM tree structure allows SmartEngine to handle high write throughput while maintaining efficient query performance by keeping the most recent data easily accessible in higher levels.
Extent
An Extent is the physical storage unit within SmartEngine, representing a contiguous block of data stored on S3. Extents store the actual data in the system, including compressed and compacted data from the LSM tree. As data is flushed and compacted from higher levels (L0 → L1 → L2), it is written into extents, which can then be uploaded to S3 for long-term storage.
Block
A block in SmartEngine is the fundamental unit of data storage within an Extent. The extent is subdivided into blocks, each of which is typically 16KB in size. Each block contains a portion of the table's or index's data, and multiple blocks are grouped together within an extent. Blocks are compressed and sorted to optimize both storage space and query performance. When data is read from S3, it could be retrieved in block-sized chunks, allowing SmartEngine to efficiently manage I/O operations.
Manifest log
The manifest log is a log that records metadata and state changes related to the internal workings of SmartEngine. This includes structural changes to the LSM tree, schema updates, and other important events that need to be persisted for recovery and consistency. The manifest log helps ensure that SmartEngine can recover its internal state even in the case of a failure.
MetaSnapshot
A MetaSnapshot is a snapshot of SmartEngine's metadata, capturing the state of the LSM tree, extents, and other relevant metadata at a specific point in time. MetaSnapshots are periodically taken and uploaded to S3 as part of the overall data durability strategy, enabling SmartEngine to restore its state during recovery.
Tablespace
A Tablespace manages all the Extents associated with a table and its indexes, acting as a logical container that ensures efficient organization and storage. Extents within a tablespace are periodically compacted to reduce fragmentation and improve performance. By isolating each table and its indexes in their own tablespace, this design enhances scalability.
Write Path
The write path involves multiple stages, including the WAL, MemTable, flush, and compaction. Below is an overview of the different stages involved in the SmartEngine write path.
Writing WAL
When the MySQL Server writes data to SmartEngine, the data is first written to the WAL, which is similar to InnoDB’s redo log. WAL ensures durability by logging changes before they are fully committed to the storage system. Every write operation is appended to the WAL to safeguard the data in case of a crash or failure. If a system failure occurs, the WAL can be replayed during recovery to restore the in-memory state.
MemTable
Data is written to the MemTable after being recorded in the WAL. Since the MemTable is in-memory, it allows for fast writes and efficient retrieval of recently written data. The MemTable is limited in size. Once it reaches a predefined size limit, or when the WAL grows too long, a flush process is triggered.
Flush to L0
When the MemTable becomes too large or the WAL reaches a certain size, a flush operation is initiated. The flush writes the contents of the MemTable to S3, marking the start of the data lifecycle within the LSM tree.
During the flush process, the data from the MemTable is written into one or more extents. These extents are stored in L0, the first level of the LSM tree. Each extent is an individual object in S3, identified by a unique ExtentID. The extent is subdivided into blocks, each of which is typically 16KB in size. When an extent exceeds 2MB, a new extent is automatically created.
Once the flush is complete, metadata about the newly created extents is recorded in the manifest log. The manifest log does not store the actual data but contains the metadata required to map the extents in the LSM tree, such as the extent's ID, size, start key, end key, and its position in the LSM tree. The flush operation is only considered fully complete when the manifest log is also uploaded to S3, ensuring that the metadata and the flushed data are available across the distributed system and visible to other nodes.
Compaction
As data accumulates in the LSM tree, a process called compaction is automatically triggered to maintain the efficiency of the structure.
Compaction is responsible for merging extents from different levels of the LSM tree (starting from L0) and reclaiming non-visible data, such as deleted or updated entries. During compaction, the system reads data from multiple extents, merges them, and writes the result into new extents. The old, obsolete extents are then deleted from S3. Compaction helps reduce the number of extents in each level, improving read performance by reducing the number of disk I/O operations required to retrieve data. Like the flush process, compaction updates the manifest log file to record the changes in extent metadata, ensuring consistency and durability of the new state of the LSM tree.
Checkpoint
In SmartEngine, all metadata changes (modifications to the LSM structure) are appended as log entries to the manifest log file. As the manifest log grows longer, it eventually needs to be consolidated by merging all log entries into a single comprehensive snapshot, known as a checkpoint.
A checkpoint represents the entire state of the metadata at a given point in time and consolidates all previous log entries. Combined with the in-memory data (the MemTable), the checkpoint forms a snapshot of the SmartEngine's state.
This checkpoint mechanism ensures data consistency and efficient recovery, as the engine can quickly reconstruct the state by loading the checkpoint, avoiding the need to replay all individual log entries from the manifest log.
Read path
The read path in SmartEngine starts when a query requests specific data, such as a range of rows or a specific key. The engine first checks the MemTable. If it's a point query, it then checks the Row Cache. If the data is not found, the engine proceeds to search the LSM tree (L0, L1, L2, etc.). While reading from the LSM tree’s extents, the engine will sequentially check the Block Cache (in-memory) and the Persistent Cache (optional). If the requested data is not found in any of these layers, SmartEngine may need to access S3 for long-term storage.
The goal of SmartEngine’s read path is to traverse these structures in an optimal way, retrieving the requested data while minimizing I/O operations and ensuring consistency.
MemTable
The first stop in SmartEngine’s read path is the MemTable, which is a sorted, in-memory data structure where newly written data is stored before being flushed to disk.
- Fast Access: MemTable provides fast, in-memory access to the most recent data.
- Sorted Data: Since the MemTable is sorted, lookups, especially for point queries or small ranges, are very efficient.
If the requested data is found in the MemTable, the query is immediately satisfied, and no further lookup is necessary. If the data is not found, the read path proceeds to the next step.
Row Cache
If the requested data is not found in the MemTable, SmartEngine checks the Row Cache, which is an in-memory cache that stores frequently accessed rows. Unlike the Block Cache, which caches entire blocks of data, the Row Cache stores individual rows, allowing for fine-grained lookups.
- Fast Access: If the requested row is found in the Row Cache, SmartEngine can immediately return the result without traversing the rest of the read path, drastically reducing latency.
- Efficiency: The Row Cache is particularly useful for workloads with frequent point queries, as it avoids the overhead of loading entire blocks from disk or block cache.
However, it is important to note that Row Cache can only accelerate point lookups and does not support range queries.
Extents Lookup
If the data is not found in the MemTable, SmartEngine continues the search in the LSM tree. The LSM tree consists of three levels (L0, L1, L2), each containing immutable extents (also called SSTables or Sorted String Tables in other LSM implementations).
Level 0 (L0)
L0 contains flushed MemTables that have recently been written to disk. Since L0 files are unsorted and can overlap, the engine may need to scan multiple L0 extents to satisfy the query.
Level 1 and L2 L1 and subsequent levels are larger and non-overlapping, meaning each key exists in only one extent per level. These levels are sorted and compacted, making reads more efficient as the engine only needs to search a single extent in each level. Compaction ensures that older data is compacted into larger, more efficient extents, reducing the number of files that need to be searched.
As the query progresses through the levels, the engine looks for the requested data in each level, starting from L0 and continuing downward. If the data is found in any level, the query is satisfied, and the search stops.
Parallel Reads: In some cases, SmartEngine may parallelize reads across different levels of the LSM tree to reduce latency.
Bloom Filters and Indexes
To optimize the read path, SmartEngine uses Bloom filters and indexes to reduce the number of extents that need to be checked during a read.
- Bloom Filters: Each block has an associated Bloom filter that tells the engine whether the requested key might exist in that block. If the Bloom filter returns a negative result, SmartEngine can skip that block entirely, saving time. The Bloom filters are stored in the last block of each extent, known as the Block Index.
- Block Indexes: An extent is divided into multiple blocks, and the last block of each extent is an index that tells the engine where to find specific keys within the extent. This prevents a full scan of the extent and allows SmartEngine to jump directly to the relevant block, further optimizing the read process.
Block Cache
SmartEngine uses an in-memory block cache (analogous to InnoDB's buffer pool) to store frequently accessed blocks. If a requested block is already present in the cache, the engine can serve the query from memory, avoiding a disk I/O operation.
The Block Cache significantly improves read performance by keeping "hot" data block in memory, reducing the need for expensive disk reads. This is particularly beneficial in read-heavy workloads, where the same data is accessed repeatedly. A high Block Cache hit rate is often a key indicator of good read performance, as more data is served from memory rather than disk.
Persistent Cache
The Persistent Cache in SmartEngine is an optional, disk-based cache (which could be backed by EBS or instance store) that stores frequently accessed extents that are located on S3. This cache acts as a middle layer between S3 and the in-memory Block Cache, helping to improve read performance by keeping more frequently accessed data on faster, local disk storage. When a block is not found in the Block Cache, SmartEngine checks the Persistent Cache before retrieving it from S3.
When using EBS as the storage medium for Persistent Cache, EBS bandwidth can easily become a bottleneck. For example, AWS gp3 EBS provides a default 125MB/s of free bandwidth, which may be insufficient in high concurrency or high throughput scenarios, leading to performance bottlenecks. Therefore, if you need to enable Persistent Cache, we recommend using instance store (local NVMe SSD).
Reading from S3
SmartEngine supports offloading large amounts of data to S3 for long-term storage. If the requested data has been compacted and uploaded to S3, the engine will retrieve it from there.
This is typically the last resort on the read path, as accessing data from S3 is slower than reading from local EBS or memory. However, SmartEngine ensures that only data that is infrequently accessed or no longer needed for immediate reads is offloaded to S3.