Replication
Overview
WeSQL replication is designed as a cloud-native replication solution that uses object storage as a medium for binlog copying between one WeSQL database (known as the Source) and one or more other databases (known as Replica). WeSQL replication uses asynchronous replication, periodically detecting changes in the binlog in the Source object storage to replicate data to the local Replica Server and replay it. Therefore, the data on the Replica Server will lag behind the Source database, but the data read by the application from the Replica Server can always be guaranteed to be a consistent snapshot of the Source database. Unlike MySQL's asynchronous replication model, the application will not read inconsistent or uncommitted data from the Replica. This is because the WeSQL Source database ensures that only binlogs that have reached consensus or have been committed are persisted to object storage.
WeSQL Replication Architecture
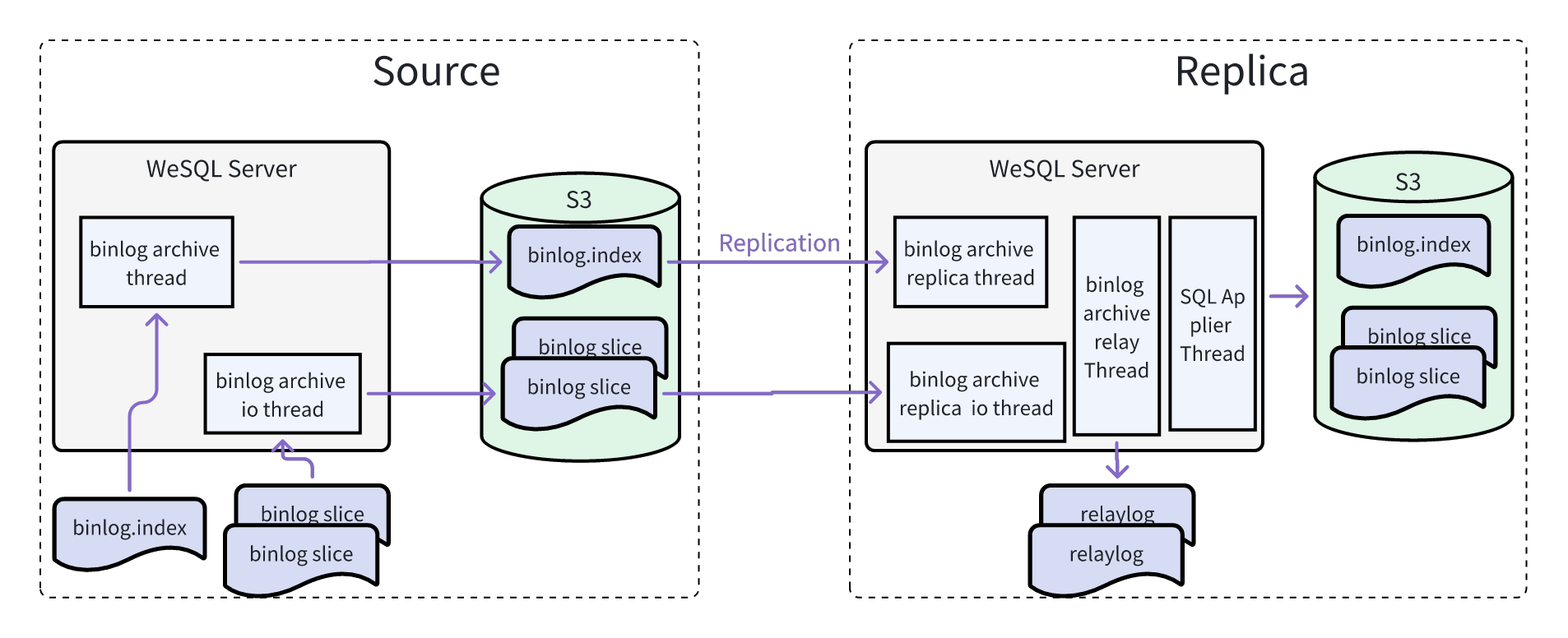
- The Replica will create four types of threads:
- Binlog Archive Replica thread(main control thread, 1): Responsible for creating other threads and detecting incremental binlog updates from the source object storage.
- Binlog Archive Replica IO thread(binlog_archive_parallel_workers=4): Responsible for concurrently pulling binlog objects from the source object storage into the local cache.
- Binlog Archive Replica Relay thread(1): Responsible for sequentially writing events from the binlog objects in the local cache to the relay log.
- SQL Applier thread(replica_parallel_workers=4): Responsible for concurrently replaying the relay log (the replay logic is consistent with MySQL’s replay logic).
- When the WeSQL Replica starts for the first time (after the clone is completed), it automatically uses the binlog end position recorded in the source object storage during the cloning process (which is stored as a parameter after successful cloning) as the starting replication position for the Replica, and creates the
binlog_archive_replicachannel. - The Replica thread periodically scans the binlog in the source database object storage to detect if there are any incremental binlog slices, scanning the binlog in units of slices. The default scanning interval is 1 second, but it can be dynamically configured via parameters.
- If new binlog slices are found, the IO thread is responsible for concurrently pulling binlog objects.
- Once the binlog slice objects are pulled, they are sequentially written into the relay log by the relay thread.
- The SQL Applier thread continuously replays the incremental relay log.
WeSQL Replication Setup
- Clone a new database from the source database object storage by setting the parameter
initialize_from_source_objectstore=true. Refer to clone wesql - Configure Replica Server:
- set
relay_log_recovery=ON. - set
binlog_archive_replica=true.
- set
- Check the replica’s status:
select * from mysql.slave_relay_log_info where Channel_name='binlog_archive_replica';
Advantages of WeSQL Replication:
- Scale-out across object storage: Supports creating multiple Replica Servers across AZs within a region, across regions, or even across providers to enhance application read scaling capabilities.
- Disaster recovery across object storage: Supports creating Replica Servers across AZs within a region, across regions, or even across providers to enhance disaster recovery capabilities.
- Zero impact on the database: There is no interaction between the WeSQL Replication Source Server and Replica Server, so the performance of the Source Server is not affected. The Replica Server will not interrupt replication due to Source server failures.
- Data consistency read guarantee: The data read by the application from the Replica Server can always be guaranteed to be a consistent snapshot of the Source database, meaning the data read is always committed data.
- Simple setup: Automatically creates WeSQL replication channels and supports automatic fault recovery during the replication process of the Replica Server.
WeSQL Replication Limitations
- WeSQL Replication relies on the
relay_log_recovery=ONparameter. When the Replica node restarts, it will use the replay log’s replay position as the replication starting point to ensure only binlogs that have not been replayed are pulled. - WeSQL Replication supports only asynchronous replication.