Host Database Serverlessly On AWS Fargate - Just Like Your Applications

Running a database in the cloud often means paying for idle capacity and dealing with persistent storage overhead. AWS ECS + Fargate changes that equation by letting you pay only for actual compute time and seamlessly integrate with S3 for storage, effectively separating compute from data. This guide shows you how to host a MySQL-compatible database (WeSQL) using Fargate’s pay-as-you-go model while storing your data durably on S3—so you don’t pay for idle compute.
What We’ll Build
By following this guide, you’ll launch a MySQL-compatible database that:
- Runs on AWS Fargate (no dedicated servers)
- Uses S3 for permanent data storage
- Starts/stops on demand, ensuring you only pay when it’s actually running
Here’s the architecture and resource dependencies:

Prerequisites
- An AWS account with appropriate permissions
- Basic understanding of AWS VPC, ECS, IAM
- A VPC with public subnets and security groups configured
Networking Requirements
- A VPC with a public subnet
- An Internet Gateway attached
- A security group allowing:
- Inbound: TCP port 3306 (MySQL)
- Outbound: All traffic
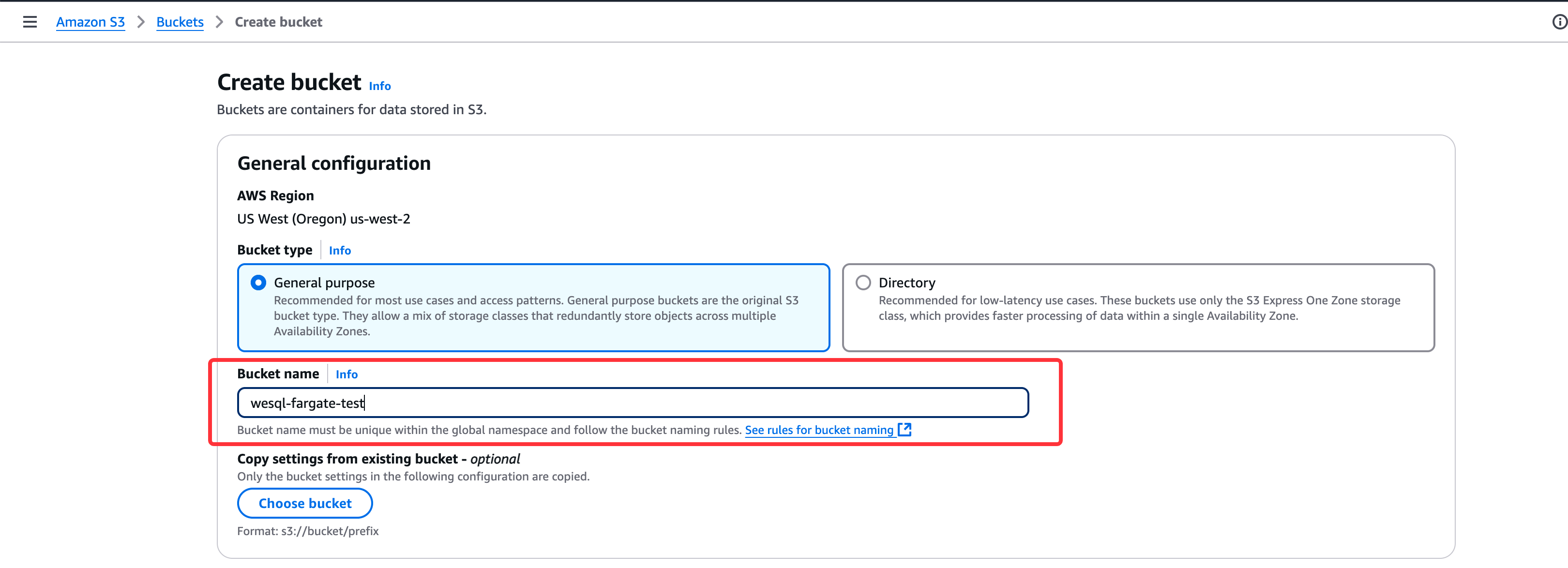
Create S3 Bucket
Create an S3 bucket for database files—this is where WeSQL will store all data.
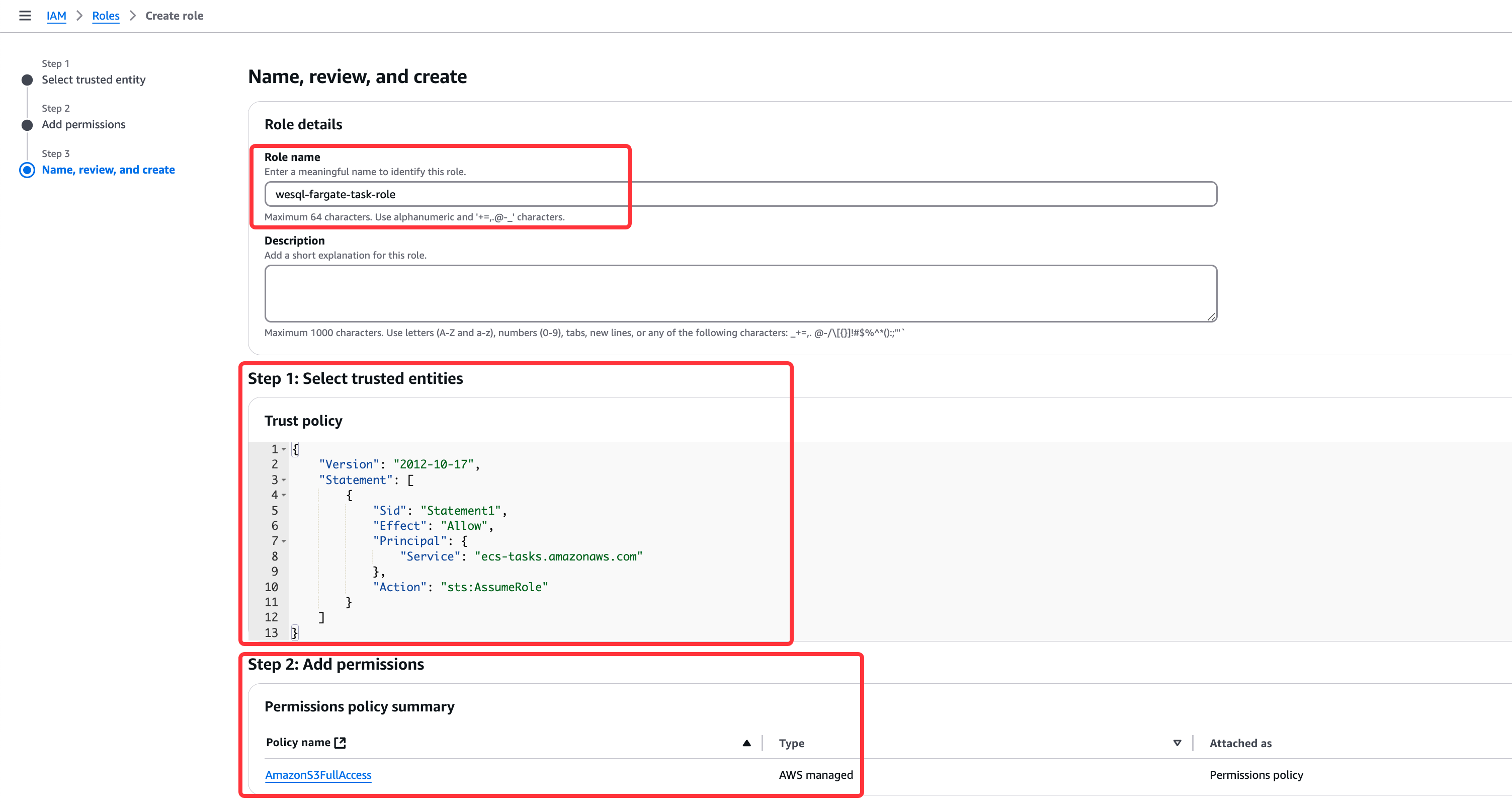
Create IAM Roles
Next, create an IAM role to grant ECS tasks permission to access the S3 bucket. Attach this role to your task definition.
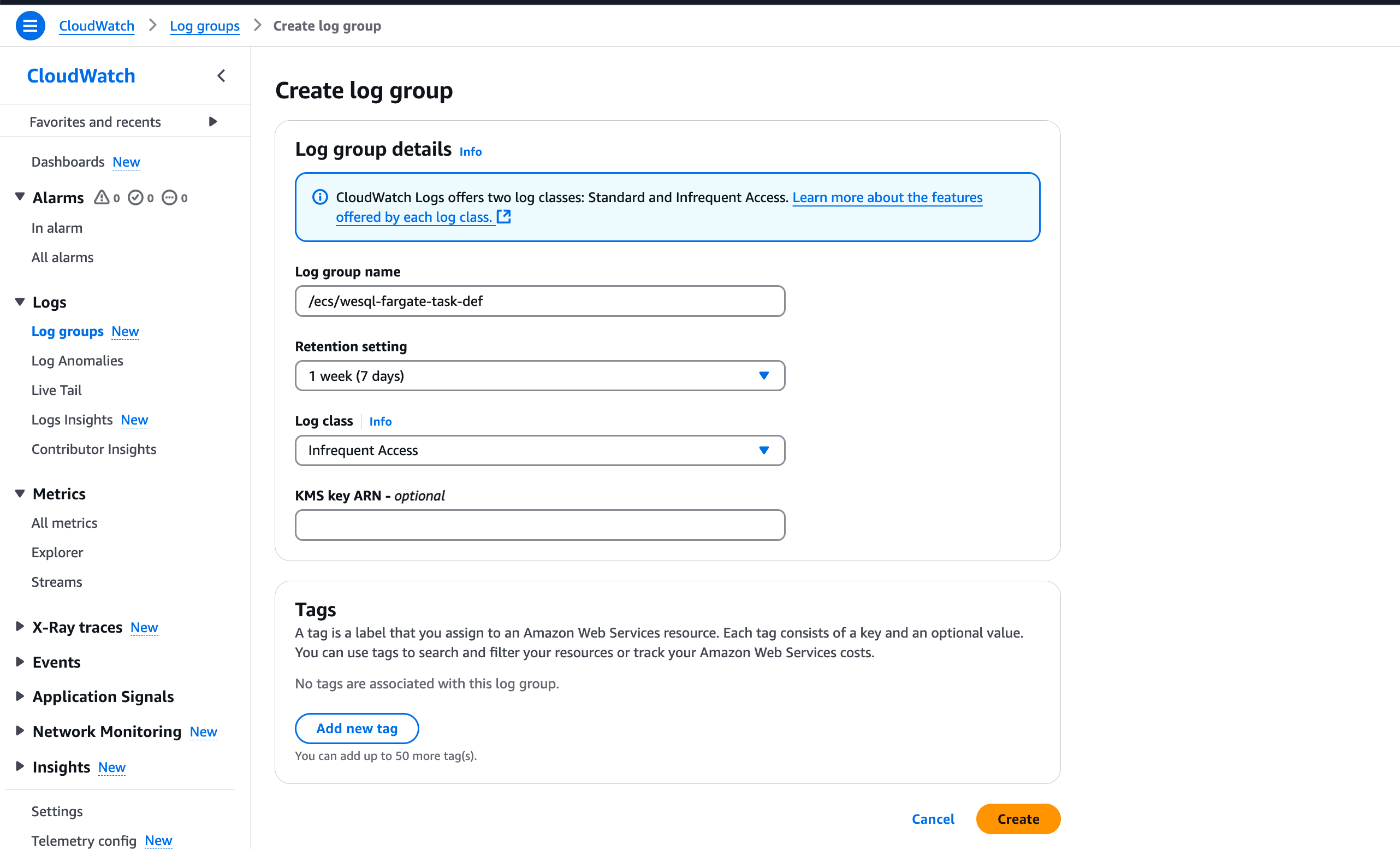
Create Log Group
Set up a CloudWatch Log Group to capture container logs:
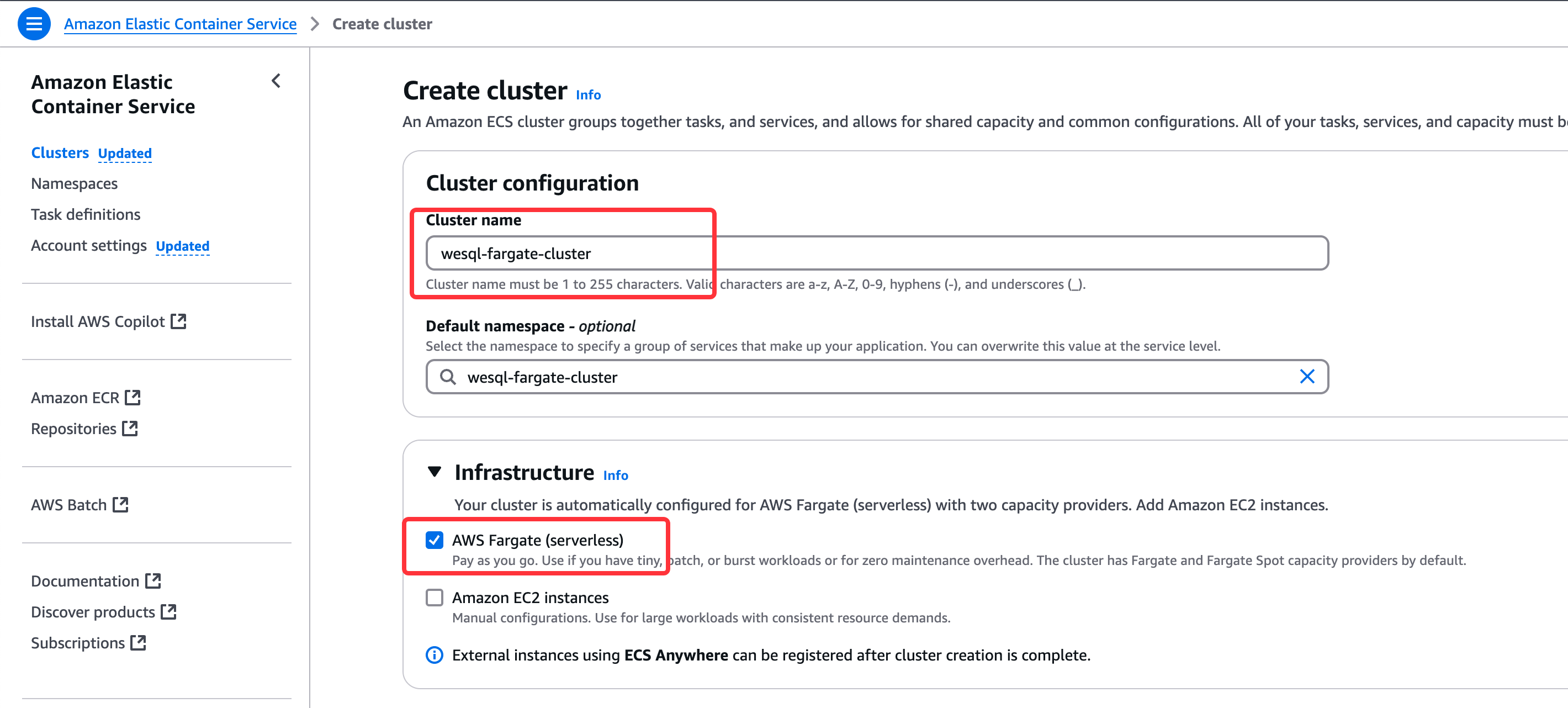
Create ECS Cluster
Create an ECS cluster to organize Fargate tasks:
Create ECS Task Definition
Define how your WeSQL container runs in the ECS Task Definition:
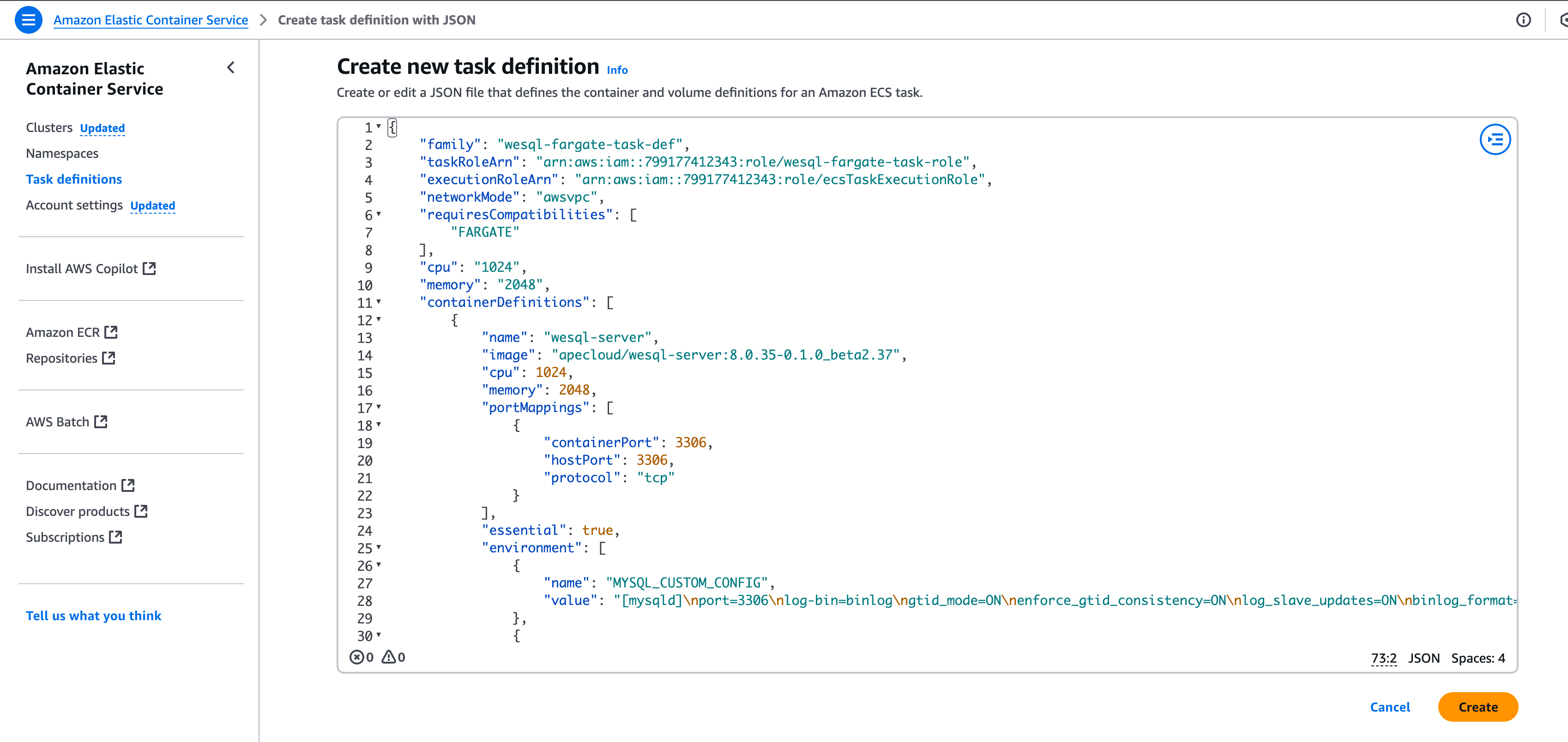
Below is an example JSON for WeSQL:
{
"family": "wesql-fargate-task-def",
"taskRoleArn": "<your-task-role-with-s3-permission>",
"executionRoleArn": "<ecs-default-ecsTaskExecutionRole>",
"networkMode": "awsvpc",
"requiresCompatibilities": ["FARGATE"],
"cpu": "1024",
"memory": "2048",
"containerDefinitions": [
{
"name": "wesql-server",
"image": "apecloud/wesql-server:8.0.35-0.1.0_beta2.37",
"cpu": 1024,
"memory": 2048,
"portMappings": [
{
"containerPort": 3306,
"hostPort": 3306,
"protocol": "tcp"
}
],
"essential": true,
"environment": [
{
"name": "MYSQL_CUSTOM_CONFIG",
"value": "[mysqld]\nport=3306\nlog-bin=binlog\ngtid_mode=ON\nenforce_gtid_consistency=ON\nlog_slave_updates=ON\nbinlog_format=ROW\nobjectstore_provider=aws\nrepo_objectstore_id=tutorial\nbranch_objectstore_id=main\nsmartengine_persistent_cache_size=1G"
},
{
"name": "WESQL_OBJECTSTORE_ACCESS_KEY",
"value": "<REPLACE_ME>"
},
{
"name": "WESQL_DATA_DIR",
"value": "/data/mysql/data"
},
{
"name": "WESQL_OBJECTSTORE_SECRET_KEY",
"value": "<REPLACE_ME>"
},
{
"name": "MYSQL_ROOT_PASSWORD",
"value": "passwd"
},
{
"name": "WESQL_CLUSTER_MEMBER",
"value": "127.0.0.1:13306"
},
{
"name": "WESQL_OBJECTSTORE_REGION",
"value": "us-west-2"
},
{
"name": "WESQL_LOG_DIR",
"value": "/data/mysql/log"
},
{
"name": "WESQL_OBJECTSTORE_BUCKET",
"value": "wesql-fargate-test"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/wesql-fargate-task-def",
"awslogs-region": "us-west-2",
"awslogs-stream-prefix": "ecs"
}
}
}
]
}
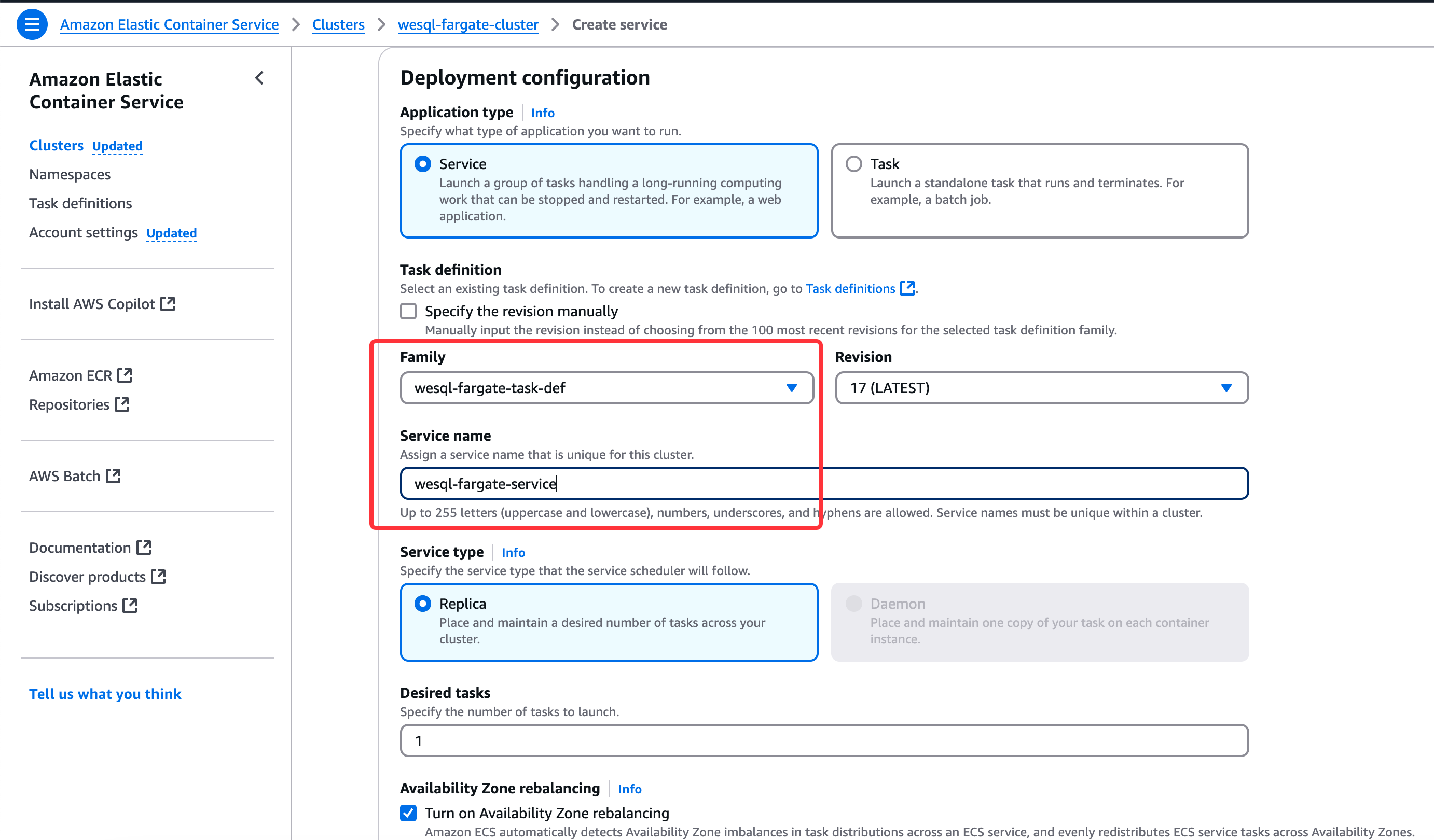
Create ECS Service
Now create an ECS Service to keep the task running:
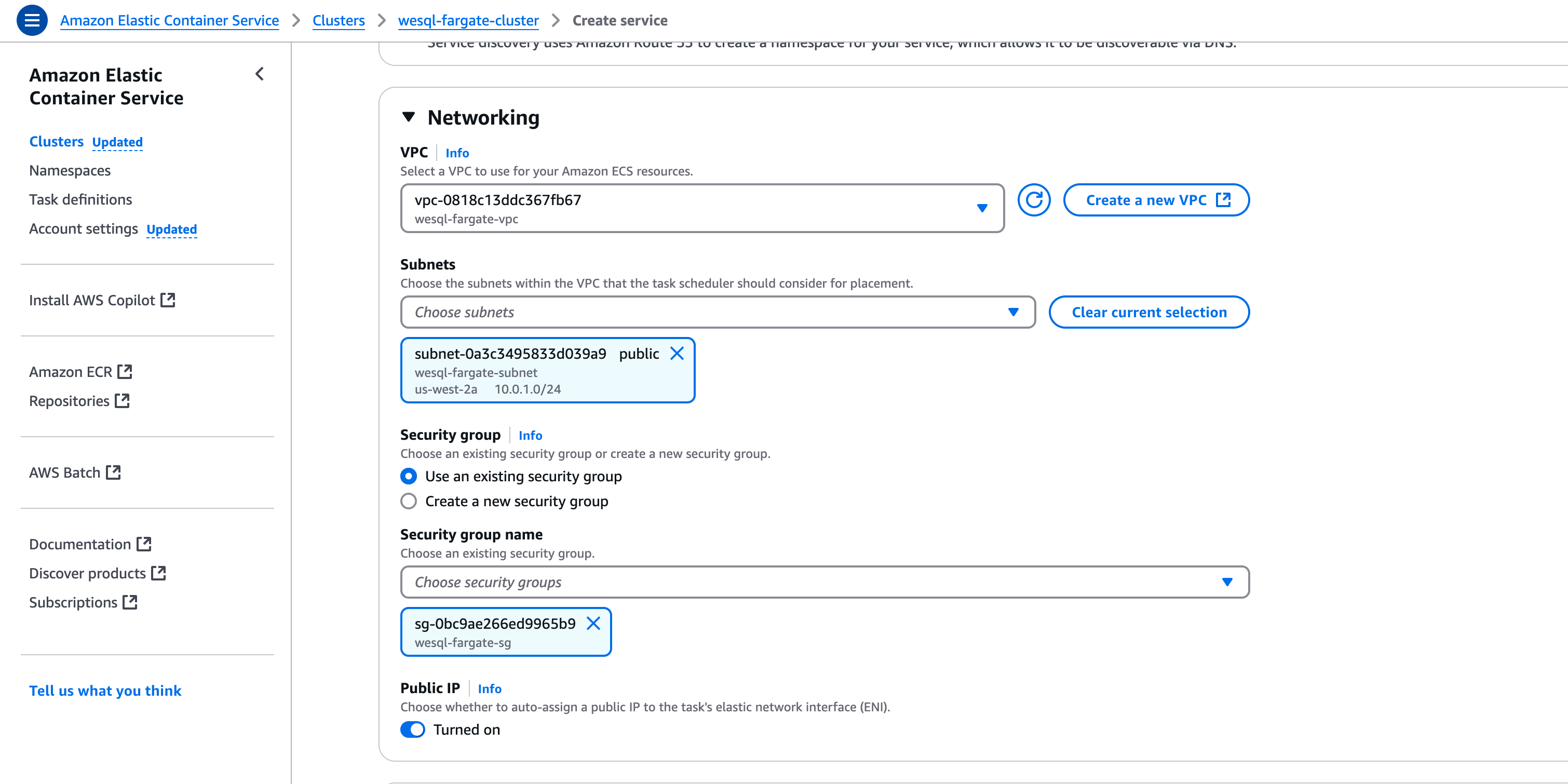
Select the right subnets and security group:
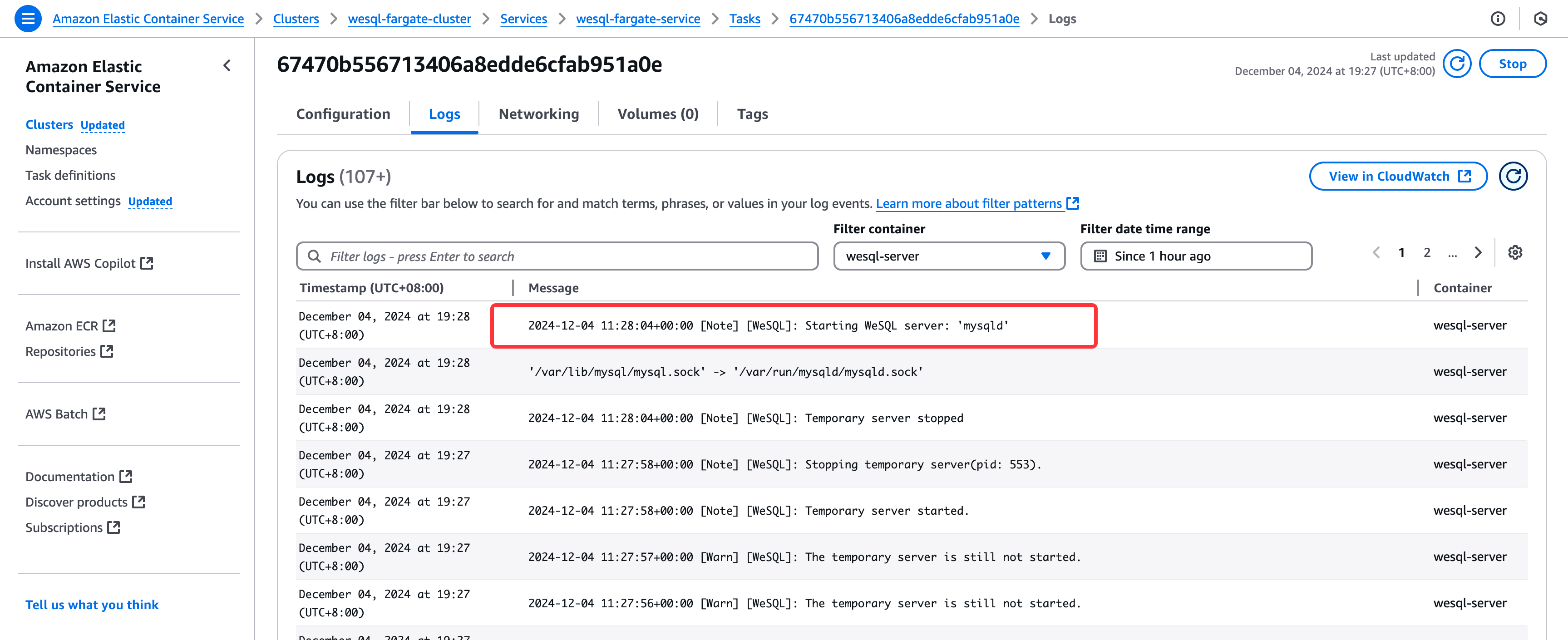
Check logs in CloudWatch to confirm the database is running:
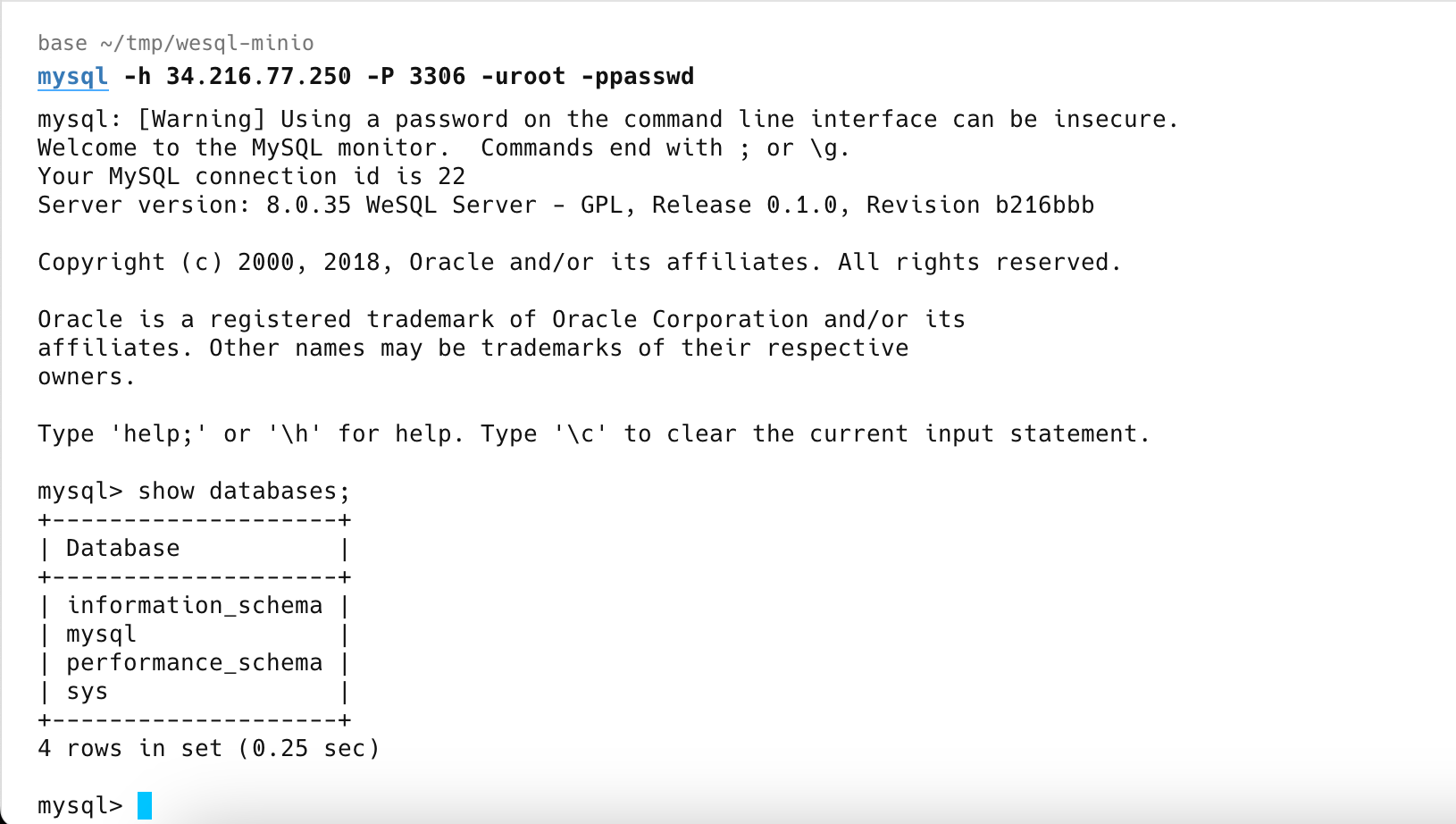
Connect to the Database
With the service active, you can connect to WeSQL using any MySQL client:
mysql -h <FARGATE_PUBLIC_IP> -P 3306 -uroot -ppasswd
Pause and Resume the Database
WeSQL uses S3 for storage, so the database container in Fargate is stateless and can be stopped and restarted without losing data. This is ideal for saving costs—simply stop the database when not in use:
# Pause the database (set desired count to 0)
aws ecs update-service \
--cluster <your-cluster-name> \
--service <your-service-name> \
--desired-count 0
# Resume the database (set desired count to 1)
aws ecs update-service \
--cluster <your-cluster-name> \
--service <your-service-name> \
--desired-count 1
Or automate this with AWS Lambda:
import boto3
ecs = boto3.client('ecs')
def lambda_handler(event, context):
action = event.get('action')
cluster = event.get('cluster')
service = event.get('service')
desired_count = 0 if action == 'pause' else 1
ecs.update_service(
cluster=cluster,
service=service,
desiredCount=desired_count
)
Other Considerations
- Service Discovery: Use AWS Service Discovery for a stable DNS endpoint.
- Secrets Management: Store credentials in AWS Secrets Manager.
- Scheduled Start/Stop: Use AWS EventBridge to automate cost-saving start/stop schedules.
Automation with Python Scripts
Check out this simple Python script using AWS SDK (boto3) to automate resource creation. You can also adapt it or use Terraform, CloudFormation, etc.
By combining Fargate’s pay-as-you-go model with S3-based storage, you get a flexible “serverless” MySQL experience—no idle compute charges, no bulky EBS volumes, just on-demand database hosting that fits your actual usage.