WeSQL Disaster Recovery across Regions - WeSQL Replication Solution with S3 storage

This blog introduces how to build a disaster recovery cluster across AWS Regions using WeSQL Replication. WeSQL Replication is a feature of WeSQL that provides a simple and efficient replication solution based on S3 Storage. For more information about WeSQL Replication, please refer to WeSQL Replication.
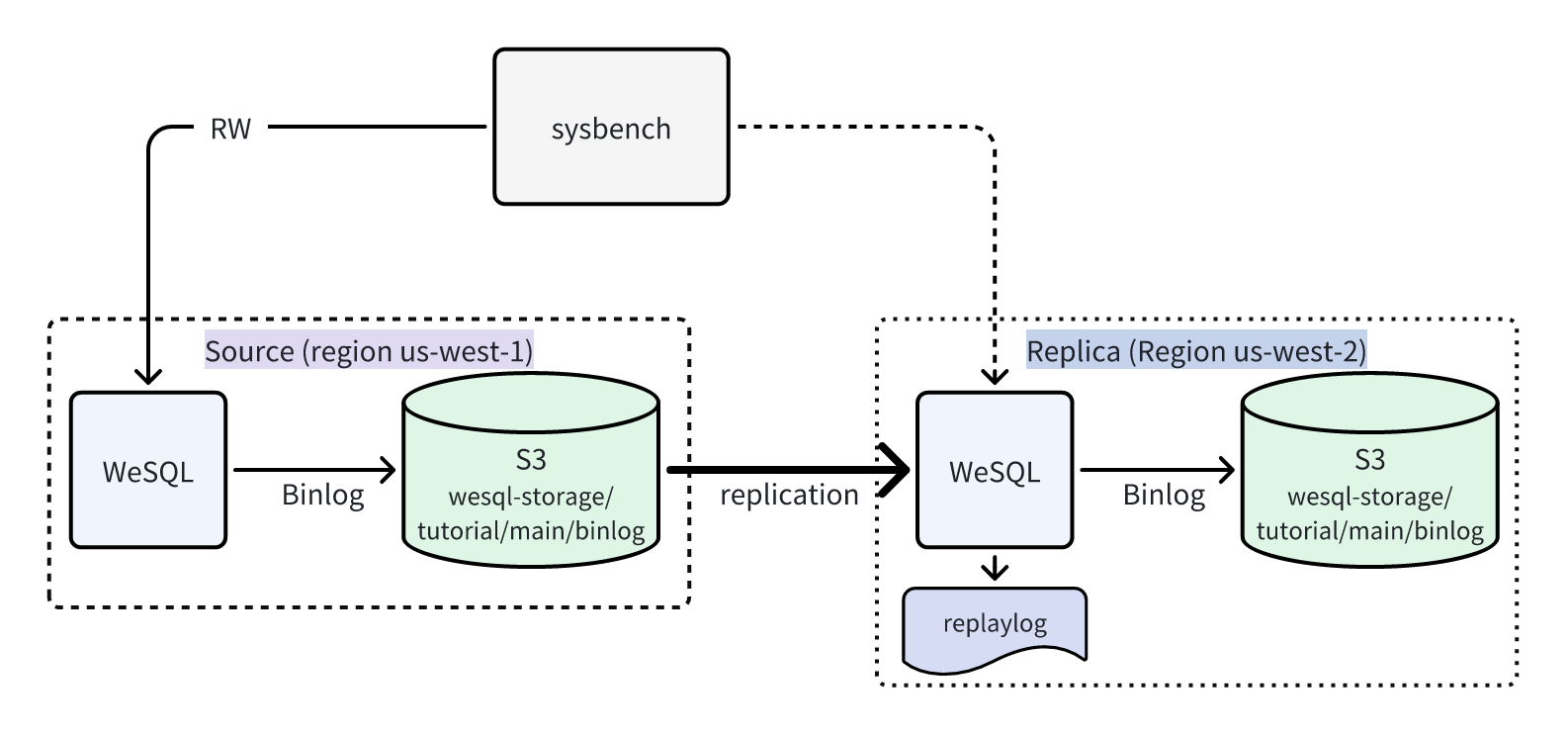
WeSQL Disaster Recovery Cluster Deployment Architecture
We use AWS as an example for deployment, deploying WeSQL disaster recovery cluster in two different regions.
The Primary Database is deployed in Region us-west-1, and the Replica Database is deployed in Region us-west-2.
The Replica server synchronizes Binlog from the Primary Server's S3 Bucket to the local RelayLog.
The Replica Server replays the RelayLog and applies it to its own database, then persists it to its own S3 Bucket.
Deploying the Disaster Recovery Cluster
Create Source database in Region us-west-1
Start a EC2 instance, create a WeSQL Database, set the public IP source_public_ip, and open port 3306 in the security group.
Refer to Start A WeSQL-Server Container
- Set S3 Access Key and Secret Key
cat wesql.env
WESQL_OBJECTSTORE_ACCESS_KEY=your-access-key
WESQL_OBJECTSTORE_SECRET_KEY=your-access-key
- Start WeSQL Source Server as Primary Database.
docker run -itd --network host --name wesql-source \
-e MYSQL_CUSTOM_CONFIG="[mysqld]\n\
port=3306\n\
log-bin=binlog\n\
gtid_mode=ON\n\
enforce_gtid_consistency=ON\n\
log_replica_updates=ON\n\
binlog_format=ROW\n\
objectstore_provider=aws\n\
objectstore_region=us-west-1\n\
objectstore_bucket=wesql-storage\n\
repo_objectstore_id=tutorial\n\
branch_objectstore_id=main\n\
smartengine_persistent_cache_size=1G" \
-v ~/wesql-local-dir:/data/mysql \
-e WESQL_DATA_DIR=/data/mysql/data \
-e WESQL_LOG_DIR=/data/mysql/log \
-e WESQL_CLUSTER_MEMBER=127.0.0.1:13306 \
-e MYSQL_ROOT_PASSWORD=passwd \
--env-file=./wesql.env \
apecloud/wesql-server:8.0.35-0.1.0_beta5.40
Create Replica database in Region us-west-2
Start a EC2 instance, create a WeSQL Replica Database, set the public IP replica_public_ip, and open port 3306 in the security group.
Refer to Clone A WeSQL-Server Container, clone the Source Database to the Replica Database and enable the replication feature binlog_archive_replica.
- Set the Replica node S3 and Source S3 Access Key and Secret Key.
your_source_access_keyandyour_source_secret_keyare the Source Database S3 Access Key and Secret Key.
cat wesql-local.env
WESQL_OBJECTSTORE_ACCESS_KEY=your_access_key
WESQL_OBJECTSTORE_SECRET_KEY=your_secret_key
WESQL_SOURCE_OBJECTSTORE_ACCESS_KEY=your_source_access_key
WESQL_SOURCE_OBJECTSTORE_SECRET_KEY=your_source_secret_key
- Start WeSQL Replica Server as Secondary Database.
docker run -itd --network host --name wesql-secondary \
-e MYSQL_CUSTOM_CONFIG="[mysqld]\n\
port=3306\n\
server_id=2\n\
read_only=ON\n\
log_bin=binlog\n\
gtid_mode=ON\n\
enforce_gtid_consistency=ON\n\
log_replica_updates=ON\n\
binlog_format=ROW\n\
sync_relay_log=10000\n\
relay_log_recovery=ON\n\
relay_log=relay-bin\n\
objectstore_provider='aws'\n\
objectstore_region='us-west-2'\n\
objectstore_bucket='wesql-storage'\n\
repo_objectstore_id='tutorial'\n\
branch_objectstore_id='main'\n\
initialize_from_source_objectstore=true\n\
binlog_archive_replica=true\n\
source_objectstore_smartengine_data=true\n\
source_objectstore_provider='aws'\n\
source_objectstore_region='us-west-1'\n\
source_objectstore_bucket='wesql-storage'\n\
source_objectstore_repo_id='tutorial'\n\
source_objectstore_branch_id='main'" \
-v ~/wesql-local-dir:/data/mysql \
-e WESQL_DATA_DIR=/data/mysql/data \
-e WESQL_LOG_DIR=/data/mysql/log \
-e WESQL_CLUSTER_MEMBER='127.0.0.1:13306' \
-e MYSQL_ROOT_PASSWORD=passwd \
--env-file=./wesql-local.env \
apecloud/wesql-server:8.0.35-0.1.0_beta5.40
- Create schema, user, and the required permissions.
mysql> CREATE SCHEMA sbtest;
mysql> CREATE USER sbtest@'%' IDENTIFIED BY 'password';
mysql> GRANT ALL PRIVILEGES ON sbtest.* to sbtest@'%';
Sysbench Test
Start a EC2 instance, start sysbench test, and connect to the Source Database.
- Prepare sysbench data.
docker run --network host --rm \
apecloud/customsuites:latest \
sysbench \
--db-driver=mysql \
--report-interval=2 \
--tables=4 \
--table-size=250000 \
--threads=8 \
--time=300 \
--mysql-host=source_public_ip \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-password=password \
/usr/share/sysbench/oltp_read_write.lua \
prepar
- Run sysbench test.
docker run --network host --rm \
apecloud/customsuites:latest \
sysbench \
--db-driver=mysql \
--report-interval=2 \
--tables=4 \
--table-size=250000 \
--threads=4 \
--time=60 \
--mysql-host=source_public_ip \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-password=password \
/usr/share/sysbench/oltp_read_write.lua \
run
Verify Replication Status.
mysql> show processlist;
+-----+-----------------+-----------------+------+---------+-------+---------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+-----+-----------------+-----------------+------+---------+-------+---------------------------------------+------------------+
| 12 | event_scheduler | localhost | NULL | Daemon | 80791 | Waiting on empty queue | NULL |
| 16 | system user | | NULL | Query | 0 | waiting for handler commit | NULL |
| 17 | system user | | NULL | Query | 10 | Waiting for an event from Coordinator | NULL |
| 18 | system user | | NULL | Query | 82103 | Waiting for an event from Coordinator | NULL |
| 19 | system user | | NULL | Connect | 80791 | Waiting for an event from Coordinator | NULL |
| 20 | system user | | NULL | Connect | 80791 | Waiting for an event from Coordinator | NULL |
| 409 | root | 127.0.0.1:34106 | NULL | Query | 0 | init | show processlist |
+-----+-----------------+-----------------+------+---------+-------+---------------------------------------+------------------+
7 rows in set, 1 warning (0.00 sec)
mysql> select * from mysql.slave_relay_log_info where Channel_name='binlog_archive_replica'\G
*************************** 1. row ***************************
Number_of_lines: 14
Relay_log_name: ./relay-bin-binlog_archive_replica.000017
Relay_log_pos: 45745870
Master_log_name: binlog.000001
Master_log_pos: 777933242
Sql_delay: 0
Number_of_workers: 4
Id: 1
Channel_name: binlog_archive_replica
Privilege_checks_username: NULL
Privilege_checks_hostname: NULL
Require_row_format: 0
Require_table_primary_key_check: STREAM
Assign_gtids_to_anonymous_transactions_type: OFF
Assign_gtids_to_anonymous_transactions_value:
1 row in set (0.00 sec)
mysql> select * from mysql.slave_worker_info where Channel_name='binlog_archive_replica'\G
*************************** 1. row ***************************
Id: 1
Relay_log_name: ./relay-bin-binlog_archive_replica.000007
Relay_log_pos: 51240185
Master_log_name: binlog.000001
Master_log_pos: 438066490
Checkpoint_relay_log_name: ./relay-bin-binlog_archive_replica.000007
Checkpoint_relay_log_pos: 51188714
Checkpoint_master_log_name: binlog.000001
Checkpoint_master_log_pos: 438015019
Checkpoint_seqno: 95
Checkpoint_group_size: 64
Checkpoint_group_bitmap: 0x40401008080404028200818000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
Channel_name: binlog_archive_replica
*************************** 2. row ***************************
Id: 2
Relay_log_name: ./relay-bin-binlog_archive_replica.000007
Relay_log_pos: 51240721
Master_log_name: binlog.000001
Master_log_pos: 438067026
Checkpoint_relay_log_name: ./relay-bin-binlog_archive_replica.000007
Checkpoint_relay_log_pos: 51188714
Checkpoint_master_log_name: binlog.000001
Checkpoint_master_log_pos: 438015019
Checkpoint_seqno: 96
Checkpoint_group_size: 64
Checkpoint_group_bitmap: 0x80802010101008080808020101000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
Channel_name: binlog_archive_replica
Disaster Recovery
When the primary database is unavailable, disaster recovery can be achieved by manually switching to the replica database.
Simulate primary database unavailability
Stop the primary WeSQL Server.
docker stop wesql-source
Replica Server Consistency Check
Compare the last slice object key of the primary database's persisted Binlog with the Master_log_name and Master_log_pos columns of the replica database's slave_relay_log_info.
Ensure that the replica database has caught up to the last slice of the primary database.
Query the list of Binlog files in the Primary Server's S3 Bucket and check the key of the last Binlog file.
{binlog file name}.{raft term}.{log end position} is the key format of the Binlog slice in the S3 Bucket.
$ aws s3 ls s3://wesql-dev-snapshot/tutorial/main/binlog/binlog. --region cn-northwest-1 | tail
2025-01-21 08:08:25 559153 binlog.000001.0000000002.0433507487
2025-01-21 08:08:26 619207 binlog.000001.0000000002.0434126694
2025-01-21 08:08:27 615463 binlog.000001.0000000002.0434742157
2025-01-21 08:08:28 562365 binlog.000001.0000000002.0435304522
2025-01-21 08:08:29 567711 binlog.000001.0000000002.0435872233
2025-01-21 08:08:30 567725 binlog.000001.0000000002.0436439958
2025-01-21 08:08:31 566661 binlog.000001.0000000002.0437006619
2025-01-21 08:08:32 547891 binlog.000001.0000000002.0437554510
2025-01-21 08:08:33 496433 binlog.000001.0000000002.0438050943
2025-01-21 08:08:34 18764 binlog.000001.0000000002.0438069707
Query the Master_log_name and Master_log_pos fields from the mysql.slave_master_info table on the Replica Server.
This indicates the position of the Binlog synchronized from the Primary Server's S3 and applied to the local RelayLog.
Note that synchronizing the Binlog to the local RelayLog does not mean it has been applied to the local database.
mysql> select Master_log_name, Master_log_pos from mysql.slave_master_info where channel_name='binlog_archive_replica'\G
*************************** 1. row ***************************
Master_log_name: binlog.000001
Master_log_pos: 438069707
1 row in set (0.01 sec)
Query the Master_log_name and Master_log_pos fields from the mysql.slave_relay_log_info table on the Replica Server.
This indicates the position of the Binlog synchronized from the Primary Server's S3 and applied to the local RelayLog.
The Replica Server can only become the new Primary Server and ensure data consistency with the Primary Server after all RelayLogs have been applied to the local database.
mysql> select Relay_log_name, Relay_log_pos, Master_log_name, Master_log_pos from mysql.slave_relay_log_info where Channel_name='binlog_archive_replica'\G
*************************** 1. row ***************************
Relay_log_name: ./relay-bin-binlog_archive_replica.000007
Relay_log_pos: 51243402
Master_log_name: binlog.000001
Master_log_pos: 438069707
1 row in set (0.00 sec)
Switchover
Disable the BINLOG_ARCHIVE_REPLICATION parameter of the Replica Server to stop replication. Disable the READ_ONLY parameter to allow the Replica Server to write.
mysql> SET persist binlog_archive_replica=OFF;
mysql> SET persist read_only=OFF;
Restart the Replica Server to become the new primary database.
docker restart wesql-secondary
Sysbench Test Recovery by Connecting to the New Primary Server
Modify the sysbench connection database replica_public_ip and 3306 to the new Primary Server ip/port.
docker run --network host --rm \
apecloud/customsuites:latest \
sysbench \
--db-driver=mysql \
--report-interval=2 \
--tables=4 \
--table-size=250000 \
--threads=4 \
--time=60 \
--mysql-host=replica_public_ip \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-password=password \
/usr/share/sysbench/oltp_read_write.lua \
run