WeSQL Outperforms AWS RDS MySQL Single AZ -- 4-6x the Speed, 1/2 the cost

When people hear "S3" and "OLTP database" in the same sentence, skepticism is a common reaction. S3 is known for its low cost, but its performance and latency are often seen as unsuitable for the demands of OLTP workloads.
At WeSQL, we’ve previously explained our approach in articles like Why S3 and Persistent Cache. We use S3 for its low cost, reliability, and scalability as durable storage, while addressing performance and latency challenges with efficient write and read caching mechanisms.
Still, questions remain: Can an S3-based OLTP database perform well in practical use cases?
In this blog, we’ll show how WeSQL achieves significant storage cost savings while delivering several times the computational efficiency of AWS RDS. By combining low cost with strong performance, WeSQL challenges the traditional expectations of OLTP databases with S3-based storage.
Test Explanations
Sysbench is a widely used tool for testing OLTP performance, but its final metrics can vary greatly depending on factors like instance specifications, data volume, concurrency levels, and access patterns.
In the following Sysbench tests, we have designed the testing scenarios to closely resemble real-world business use scenarios.
Instance size
We chose the 4-core 16GB specification because This specification is widely used for small to medium-sized database instances in production, making the test results more relevant to typical workloads. And the 4-core 16GB setup provides a well-balanced combination of CPU and memory, making it suitable for handling most OLTP workloads efficiently without over-provisioning resources.
Data volume and Random type
In typical online database environments, the total data scale usually ranges from 200GB to 300GB,but only a portion of this data is actively accessed. Following the "80/20 rule," the actively accessed data typically amounts to 40GB to 60GB. To simulate real-world business scenarios, we chose a test data volume of 48GB (100 tables with 2 million rows each), which falls within this active data range. The data is accessed using a uniform pattern to ensure all parts of the dataset are evenly accessed, reflecting common usage patterns. This setup creates a realistic test environment for accurate performance evaluation.
With 16GB of memory available, the 48GB data volume exceeds the memory capacity by a large margin. This forces the system to rely on disk-based operations, effectively testing the storage engine’s performance in areas such as I/O efficiency and caching strategies.
Test Environment
-
Compute Instances:
- AWS RDS Single-AZ:
- Instance type:
db.m5d.xlarge(4vCPU, 16GB RAM) - Equipped with a 150GB local NVMe SSD for temporary storage. Persistent storage relies on EBS volumes.
- Instance type:
- WeSQL EC2:
- Instance type:
m5d.xlarge(4vCPU, 16GB RAM) - Also equipped with a 150GB local NVMe SSD, which WeSQL uses for caching to optimize read & update performance.
- Instance type:
- AWS RDS Single-AZ:
-
Storage Backend:
- AWS RDS:
- EBS gp3 volumes (200GB, 125MB/s, 3000 IOPS) for persistent storage.
- WeSQL:
- EBS gp3 volumes (100GB, 125MB/s, 3000 IOPS) for logs and metadata.
- Primary data storage is offloaded to S3.
- AWS RDS:
WeSQL is designed to minimize dependency on expensive EBS storage by leveraging S3 for data storage, so it uses a small EBS volume to store logs and metadata.
-
Client:
- Sysbench 1.0.20
- EC2:
t3a.2xlarge(8vCPU, 32GB RAM)
-
Server:
- Database Version:
- AWS RDS: 8.0.35
- WeSQL: Built on MySQL 8.0.35
- Deployment:
- Both systems were deployed as single-node instances for a direct performance comparison.
- Database Version:
-
Network Configuration:
- Availability Zone: All components—including AWS RDS, WeSQL EC2 instances, and the Sysbench client—were deployed within the same AWS availability zone to reduce network latency and ensure consistent test conditions.
Test Method
We used the Sysbench oltp_read_write workload to evaluate performance. The test configuration was as follows:
- DataSet: Prepared 100 tables, each containing 2 million rows of data.
- Concurrency: Tests were conducted with concurrency levels of 2, 4, 8, 16, 32, 64, 96, and 128.
- Duration: Each concurrency level ran for 300 seconds.
- Interval: A 60-second interval was applied before starting the next concurrency level.
Results
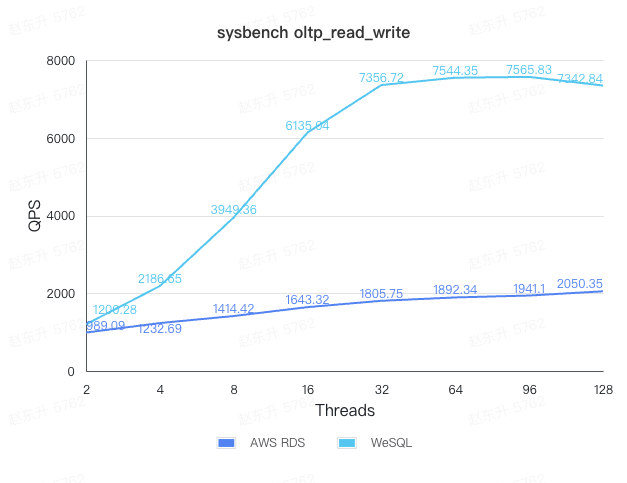
We tested both AWS RDS and WeSQL under the oltp_read_write workload using varying levels of concurrency.
throughput comparison
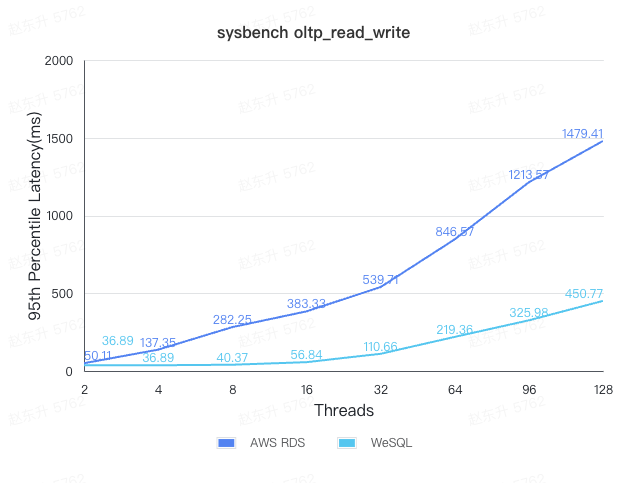
95th Percentile Latency comparison
Conclusions
Performance perspective
Based on the test results, WeSQL demonstrates peak performance that is nearly 4 times higher than AWS RDS using the same resources. Additionally, WeSQL provides significantly better latency compared to AWS RDS.
In real-world business scenarios, low latency is often critical. For instance, under a 32-thread load, WeSQL achieves a QPS of 7356.72, with a P95 latency of 110.66ms. In contrast, at the same latency level, AWS RDS achieves only 1232.69 QPS. This means that WeSQL has approximately 6 times the throughput of AWS RDS when comparing performance at equivalent latency thresholds.
Cost perspective
WeSQL also provides a significant storage cost advantage. In this test scenario, where the overall data volume is relatively small, our costs are still nearly half of AWS RDS Single-AZ. As data volume grows, this cost advantage becomes even more pronounced.
- AWS RDS Single-AZ (db.m5d.xlarge): USD 0.419 per hour
- AWS RDS Multi-AZ (db.m5d.xlarge): USD 0.838 per hour
- AWS EC2 (m5d.xlarge): USD 0.226 per hour
- Above prices are based on the us-east-1 availability zone.
Although we used a single-node deployment in our test, real-world environments typically require cross-AZ disaster recovery for resilience and fault tolerance. In WeSQL’s architecture, data durability is ensured by continuously uploading data to S3, which inherently provides cross-AZ disaster recovery capabilities. As a result, a single-data-node WeSQL deployment offers cross-AZ disaster recovery capabilities, while costing nearly 1/4 of AWS RDS Multi-AZ.
To ensure no data is lost during an AZ failure, including logs stored on EBS, WeSQL’s multi-AZ deployment adds two additional log nodes. In upcoming articles, we will provide a detailed analysis of the cost and performance differences between WeSQL and AWS RDS Multi-AZ.
Analysis
By separating the read and write QPS from the above tests for comparison, it is clear that WeSQL delivers superior performance over AWS RDS in both read and write operations.
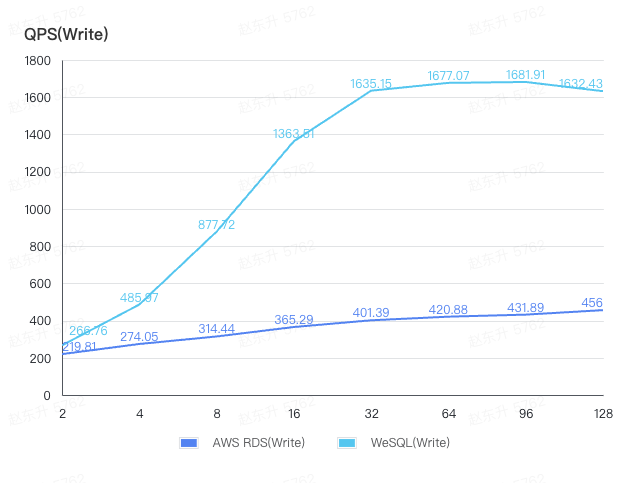
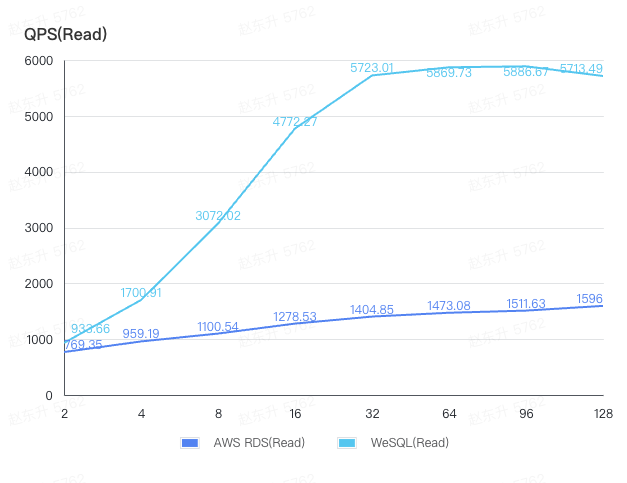
Why WeSQL outperforms AWS RDS in write performance
-
SmartEngine's Write-Optimized LSM-Tree Data Structure
The storage engine used by WeSQL, SmartEngine, is built on an LSM-Tree architecture.This design minimizes write amplification compared to the B+ Tree structure used by InnoDB in AWS RDS,resulting in more efficient write operations and better overall write performance.
-
S3's High Write Bandwidth Beats EBS GP3
SmartEngine uses S3 as the persistent storage layer, taking advantage of its higher bandwidth to accelerate flush and compaction operations.In contrast, AWS RDS relies on gp3 volumes for persistent storage,where the limited bandwidth of gp3 can become a bottleneck during dirty page flushing.This leads to I/O constraints that hinder write performance in RDS.
Why WeSQL outperforms AWS RDS in read performance
-
Low-Latency Local NVMe SSDs Cache
SmartEngine makes use of local NVMe SSDs as a read cache, which provides several key advantages:
- Separation of Read and Write I/O: By isolating reads from writes, WeSQL reduces I/O contention, resulting in smoother and faster read operations.
- Higher Performance of NVMe SSDs: Local NVMe SSDs offer significantly better performance compared to the gp3 volumes used by AWS RDS, enabling faster data access and lower read latencies.
-
Optimizations for LSM-Tree’s Read Challenges
While the LSM-Tree architecture traditionally underperforms B+ Tree in read-heavy workloads, SmartEngine incorporates a series of optimizations to bridge this gap and achieve read performance comparable to InnoDB. These include:
- Multi-priority caching mechanisms to prioritize hot data.
- Bloom filters to minimize unnecessary disk reads.
- Asynchronous I/O for better concurrency and throughput.
- Latch-free metadata operations for lower contention and higher throughput.